超节点算力革命(六)| 全球主流厂商超节点技术方案
2026-03-03
以下文章来源于微信公众号——全球计算联盟GCC
【前文回顾】超节点架构,以其超大带宽、超低时延、资源池化和高可靠性的核心特征,正成为驱动下一代人工智能、大数据和科学计算发展的关键引擎。它通过从根本上重塑数据中心的计算范式,有效解决了传统架构在面对极端计算负载时所遭遇的通信和I/O瓶颈。无论是在加速万亿参数模型的训练与推理,还是在赋能实时大数据分析和纳秒级金融交易等要求苛刻的场景中,超节点都展现出了无与伦比的潜力与价值。
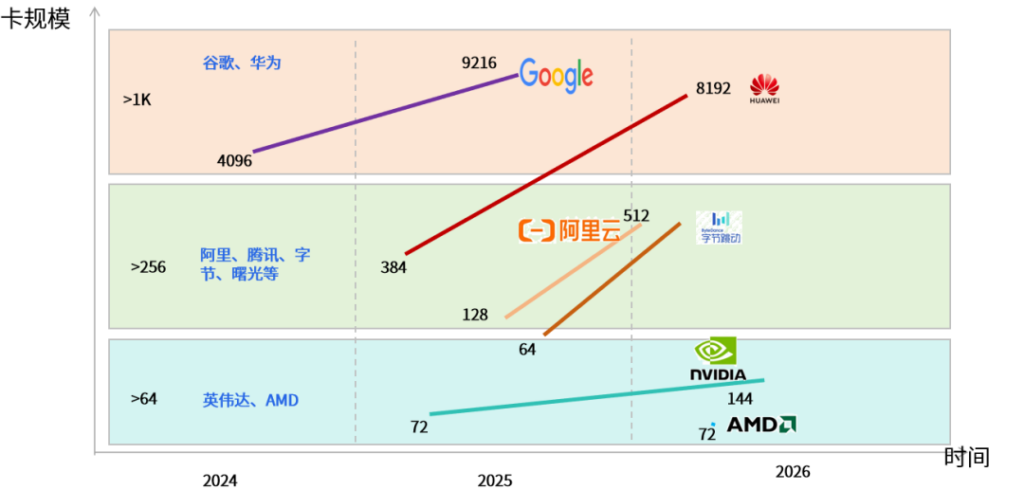
超节点技术已成全球AI算力基础设施核心引擎,呈现代际迭代与多元技术路线。国际厂商以芯片和互联技术筑壁垒,国内企业凭系统集成与开放生态实现突破,形成超大规模、大规模、中型三类超节点布局。各厂商依托差异化架构、互联技术,打造全栈算力解决方案,推动AI算力向高密度、高能效、弹性扩展演进。
超节点规模分类
基于单超节点集成的AI加速芯片数量及扩展能力,当前主流超节点方案可划分为三个层级:①超大规模超节点,华为Atlas SuperPoD A5(8192卡)、谷歌TPU v7 Pod(9216卡)为代表,这类方案通常采用多机柜级联设计,面向万亿参数级大模型训练和国家级科学计算设施,技术门槛最高、系统复杂度最大。②大规模超节点,厂商众多,涵盖阿里云磐久、中科曙光ScaleX640、字节大禹等主要方案,这一层级的方案在单柜集成度与扩展灵活性之间取得平衡,既可作为独立计算单元部署于企业数据中心,也可通过Scale-Out网络扩展至千卡级集群。③中型超节点,包括英伟达的NVL72/144方案和AMD Helios 72/144,虽然规模不大,但凭借算力芯片优势,追求极致的算力性能,也包括超聚变FusionPod(64卡)、新华三UniPod S8000(64卡)、浪潮元脑SD200(64卡)等产品,通过创新的架构设计实现较高的算力密度和能效比,更适合企业级私有化部署和边缘智能场景。
主流超节点方案01:
华为Atlas SuperPoD系列
华为Atlas SuperPoD系列是国产超节点技术的代表,涵盖三代产品演进:Atlas SuperPoD A3(当前商用版本,384卡昇腾910C)、Atlas SuperPoD A5(2026年,8192卡昇腾950DT)、Atlas SuperPoD A6(2027年,15488卡昇腾960)。定位”全球最强超节点”,主要面向国家智算中心、头部云服务商及超大规模AI研发机构,构建从机柜级到数据中心级的全栈算力基础设施。期中Atlas SuperPoD A3(CloudMatrix 384)于2025年4月在中国电信粤港澳大湾区(韶关)算力集群正式上线。2026年3 月 2 日,华为在MWC 2026 巴塞罗那正式发布Atlas 950 SuperPoD 等超节点解决方案。

Atlas SuperPoD A5的8192卡规模由128个计算柜和32个互联柜组成,采用全光连接架构,内存容量达1152TB,互联带宽16.3PB/s。Atlas SuperPoD A6在此基础上算力再度翻番,支撑百万卡级SuperCluster部署。
关键技术
①互联协议/拓扑:UB-Mesh
UB-Mesh(Unified Bus Mesh)拓扑采用混合架构设计:Rack机柜内部采用1D/2D-FullMesh全连接拓扑,通过铜缆实现计算节点间的高带宽本地互联;Rack柜间采用一层交换的Clos拓扑,通过UB Switch实现无收敛或低收敛的带宽扩展;跨机柜大规模扩展则通过全光互联方案,采用OCS(光路交换)交换机实现高效率、低时延的动态拓扑重构。
②互联方案:全光交换与电交换协同
Atlas 950 SuperPoD的16.3PB/s互联带宽由多层级交换网络共同支撑。机柜内部采用电信号交换(UB Switch),单芯片交换容量达数Tbps级别;机柜之间采用OCS光路交换,延迟较电交换降低一个数量级,且功耗显著优化。
③内存架构:HBM2e+DDR4多级缓存与统一寻址
Atlas SuperPoD实现计算、内存、网络资源的动态池化与统一访问。通过UB总线的统一内存编址机制,任意NPU可透明访问其他NPU的HBM显存及CPU的DDR内存。内存容量扩展遵循”显存+HBM+DDR+SSD“四级层次,热数据驻留于HBM,温数据缓存于DDR,冷数据下沉至SSD,由系统软件自动管理数据放置策略。
④散热技术:液冷+风冷混合与智能温控
华为超节点采用”三明治”液冷架构创新,冷板直接接触昇腾芯片及高功耗元件,冷却液在微通道内湍流流动强化换热。配合iCooling智能温控系统,动态调整冷却策略,将GPU核心温度稳定控制在45℃以下,PUE优化至1.12。Atlas SuperPoD A5单柜功率密度超过120kW,对液冷系统的流量分配、压力平衡、漏液防护提出极高要求,华为通过冗余CDU(冷却分配单元)设计和全链路漏液监测保障可靠性。
⑤可靠性:多层级容错与故障隔离
万卡级集群的可靠性设计面临”木桶效应”挑战——单卡故障若导致全集群停摆,年均故障时间将不可接受。Atlas SuperPoD采用RAS(Reliability, Availability, Serviceability)设计:硬件层面支持ECC内存、链路冗余、热插拔维护;软件层面实现故障预测、快速隔离、任务迁移,将单点故障影响域约束在最小子集。系统级可靠性目标为99.99%可用性,支撑7×24小时连续运行。
⑥软件栈:完整的软件生态
CANN(Compute Architecture for Neural Networks),提供算子开发、图编译、运行时调度等底层能力;MindSpore(昇思)开源框架支持自动并行、动静态图统一、全场景协同;ModelArts一站式AI开发平台贯通数据准备、模型开发、训练部署全流程。
机柜方案
Atlas 950 SuperPoD 的物理部署采用“计算柜+互联柜”分离架构。128个计算柜每个集成64颗昇腾950DT NPU(8节点×8卡),32个互联柜部署UB Switch和OCS光交换设备。机柜尺寸遵循标准19英寸机架规范,但深度和承重能力针对高密度部署强化设计。
供电方案采用高压直流(HVDC)技术,减少AC-DC转换损耗,提升端到端供电效率。智能功耗管理系统根据负载动态调整芯片频率和电压,在算力需求低谷期进入低功耗状态。整机柜采用预制化交付,现场仅需连接外部冷却管路和电源母线,部署周期较传统方式缩短80%以上。
路线特点与差异化
华为Atlas SuperPod的核心差异化在于全栈垂直整合与自主可控:从昇腾AI芯片、UB互联协议、机柜硬件到CANN/MindSpore软件栈,全链路自主研发,不受外部技术管制制约。这一路线在当前的地缘政治环境下具有独特战略价值,但也意味着更高的研发投入和生态建设挑战。
技术路线选择上,华为坚持开放协议的策略:UB-Mesh在机柜内部提供极致性能,同时通过UBoE和OCS实现与标准网络的互联互通,避免封闭生态的扩展性瓶颈。
主流超节点方案02:
谷歌TPU SuperPod

谷歌将SuperPod定位为”云端AI基础设施的底座”,既支撑内部搜索、广告、YouTube等核心业务的AI模型训练,也向Google Cloud客户提供按需算力服务,其打破了”只有英伟达GPU才能训练顶级模型”的神话。
谷歌的超节点战略具有鲜明的”垂直整合+云原生”特征:自研TPU芯片、自研ICI(Inter-Chip Interconnect)互联协议、自研3D Torus拓扑、配合JAX/TensorFlow框架优化,形成全栈控制。这种封闭但高效的生态,使谷歌在大模型竞赛中保持了独特的技术自主性。
关键技术
①互联协议/拓扑:ICI与3D Torus环形网络
谷歌自研的ICI(Inter-Chip Interconnect)协议是TPU SuperPod的技术基石。与英伟达NVLink的点对点全互联不同,ICI采用2D/3D Torus环形拓扑——计算节点 arranged 在多维环面网格中,每个节点与相邻节点直接相连,数据包通过维度顺序路由(dimension-ordered routing)到达目的地
②互联方案:光路交换(OCS)动态重构
TPU v4 Pod引入光路交换(Optical Circuit Switching, OCS)技术,允许动态重构Torus网络的物理连接拓扑。OCS通过MEMS微镜控制光信号路径,可根据训练任务的通信模式切换最优拓扑——数据并行任务偏好高带宽低直径拓扑,模型并行任务则需要特定的维度映射。这种”软件定义互联”能力使同一物理基础设施适配多样化工作负载。
③内存架构:HBM与超大容量片上SRAM
TPU芯片的内存架构设计独具特色:每个TPU v4芯片集成32GB HBM高带宽内存,同时配备144MB超大容量片上SRAM。大容量SRAM可将热数据驻留于芯片内部,减少对HBM的访问次数,从而提升有效算力利用率。TPU v7 Ironwood的HBM容量和带宽均较v5p翻倍,支持万亿参数模型训练。
④散热技术:数据中心级液冷系统
谷歌作为超大规模数据中心运营商,将液冷技术应用于TPU Pod的整体设计。TPU v3是Google数据中心历史上第一款引入液冷技术的芯片。TPU v4 Pod部署于定制化的液冷数据中心,PUE优化至行业领先水平。谷歌的液冷方案与服务器设计深度协同——冷却液分配、流量控制、温度监测均纳入统一管理系统,支撑4096卡级别的热管理需求。
⑤可靠性:软硬件协同容错
超大规模集群的可靠性需要软硬件协同设计。硬件层面,TPU芯片支持ECC内存保护和链路冗余;软件层面,JAX框架内置检查点(checkpoint)和故障恢复机制,训练任务可自动从最近检查点重启,最小化单点故障的影响。谷歌的Borg集群管理系统负责任务调度和资源分配,具备丰富的超大规模运维经验。
⑥软件栈与调度能力:构建了TPU完整的软件生态
JAX作为高性能机器学习研究框架,支持自动微分、XLA编译优化、SPMD(单程序多数据)并行;TensorFlow作为生产级框架,与TPU深度优化集成;XLA(Accelerated Linear Algebra)编译器将高级计算图转换为TPU高效执行代码,实现接近理论峰值的算力利用率。
机柜方案
TPU Pod的物理部署采用定制化机柜设计,非标准商用服务器形态。TPU v4 Pod的4×4×4三维环面网络对应物理空间的三维布局,相邻节点的短距离连接通过铜缆实现,跨机柜的长距离连接则采用光纤。这种”几何拓扑与物理布局同构”的设计最小化了线缆长度和信号延迟。
供电方案充分利用谷歌数据中心的规模优势,采用48V直流配电架构,减少转换损耗。机柜级液体冷却与芯片级散热协同,冷却液直接流经TPU模块的冷板。整体基础设施与谷歌云的数据中心运营深度整合,客户通过API按需获取算力,无需关注底层硬件细节。
路线特点与差异化
谷歌TPU SuperPod的核心差异化在于垂直整合的深度与云原生的成熟度。从芯片架构、互联协议、拓扑设计到编译器优化、集群调度,全链路自主可控,形成了难以复制的技术壁垒。3D Torus+OCS的拓扑创新为超大规模互联提供了不同于英伟达全互联的替代路径,在特定规模区间具有成本优势。
局限性在于生态的封闭性——TPU仅通过谷歌云提供服务,不支持私有化部署,框架选择局限于JAX/TensorFlow,对PyTorch等主流框架的支持需通过转换层实现。这一策略使TPU难以进入企业级数据中心市场,主要服务于云原生AI研究者和谷歌生态用户。随着TPU v5p向Meta、Anthropic等外部客户开放,谷歌正在谨慎地扩展其生态边界,但是否会走向完全开放仍存疑问。
主流超节点方案03:
英伟达NVL系列

英伟达NVL(NVLink)系列是全球超节点市场的标杆产品,当前主力型号为NVL72,规划型号包括NVL144(下一代架构)等。NVL72于2025年正式上市,通过第五代NVSwitch实现72个B200 GPU的全互联,总算力达720 PFLOPS(AI训练)或1440 PFLOPS(AI推理),标志着单柜级超节点的商业化成熟。
NVL72的72卡配置采用18个计算节点×4 GPU/节点的部署模式,每个节点配备2个Grace CPU与4个B200 GPU,通过NVLink-C2C实现CPU-GPU统一内存。横向扩展为576卡互联,可部署为数十万卡集群。
关键技术
①互联协议/拓扑:NVLink 5.0/6.0与全互联架构
NVLink 5.0是英伟达第五代高速互联技术,单链路带宽达1.8 TB/s,双向带宽3.6 TB/s。NVL72采用全互联拓扑,任意两GPU间通过NVSwitch直达通信,无需经过CPU或网络交换,通信延迟降至极致。第五代NVSwitch芯片集成于计算节点,支持72端口全互联。
第六代NVLink(NVLink 6.0,用于Rubin架构)每GPU带宽提升至3.6 TB/s,是上一代的2倍,是PCIe Gen6的14倍以上。Vera Rubin NVL72机架级架构实现72个GPU的all-to-all拓扑连接,总带宽达260 TB/s。
②互联方案:NVSwitch芯片与统一内存池
NVL72的核心创新在于NVSwitch芯片的应用。每个NVSwitch支持多路NVLink聚合,通过多级交换实现任意GPU之间的直接通信。
③内存架构:HBM3e与统一内存池(NVLink-C2C)
NVL72采用NVLink-C2C(Chip-to-Chip)技术,实现GPU HBM与Grace CPU LPDDR的统一内存寻址。整机柜配置:HBM高带宽内存13.5TB总容量,提供极致内存带宽;LPDDR5X大容量内存17TB总容量,支持大模型状态存储;统一内存池使所有GPU可访问整个超节点的内存资源,消除数据拷贝开销。
④散热技术:液冷设计与CDU精准控温
NVL72采用全液冷设计,CDU(Coolant Distribution Unit)精准控温,确保GPU和CPU在 optimal 温度区间运行。机柜总功耗约120kW,需要专用供电基础设施支持。
⑤可靠性:ECC内存与错误检测纠正
NVL72采用企业级可靠性设计,包括HBM ECC纠错、GPU错误检测与纠正、冗余电源和风扇等。支持热插拔维护,单节点故障不影响整体集群。
⑥软件栈与调度能力:业界最完善的AI软件生态
CUDA并行计算平台,NCCL集合通信库,TensorRT推理优化器,DGX Cloud云服务
机柜方案
NVL72采用单机柜,配置:18个计算节点(每节点2 Grace CPU + 4 B200 GPU)、4个NVSwitch托盘(实现72 GPU全互联)、CDU液冷分配单元、电源与管理系统。机柜总功耗约120kW,采用高压直流供电。整机重量与尺寸针对数据中心运输与部署优化,支持快速现场安装。
路线特点与差异化
英伟达NVL系列的核心差异化在于生态垄断优势与软硬件全栈领先。从芯片架构、互联技术、软件栈到系统集成的全栈掌控,使英伟达能够针对AI工作负载进行极致优化。快速迭代节奏(每年一代)持续拉开与追赶者的差距。局限性在于封闭生态带来的成本压力与供应商锁定风险,这为UAlink、华为灵衢等开放路线创造了市场机会。
主流超节点方案04:
AMD Helios系列

AMD Helios机架级平台基于MI455X GPU,定位”开放、高性能、高性价比”的AI算力基础设施,直接对标英伟达NVL系列,旨在打破专有生态锁定,为企业提供更灵活、成本更优的替代选择。Helios于CES 2026首次完整展示,涵盖Helios 72(72卡MI400系列)及规划中的Helios 144(144卡)等型号。
Helios 72的单个计算托盘配置4个MI455X GPU和1个”Venice” EPYC CPU,配合6个Pensando 800Gb/s SmartNIC网卡,通过PCIe 6.0或UALink连接。整机架可扩展至最多4600个CPU核心和18000个GPU核心,配备31TB HBM4,达到43TB/s的扩展带宽,提供最高2.9 ExaFLOPS的AI计算能力。
关键技术
①互联协议/拓扑:UALink(Unified Accelerator Link )
- Infinity Fabric:AMD自研的高速互联技术,用于GPU内部和GPU之间的通信。当前支持8卡全连接网状拓扑,每张卡配备7个高速链路 。
- UALink:AMD联合博通等厂商发起的开放互联联盟,旨在建立替代NVLink的开放标准。UALink支持单级交换拓扑实现超节点内Scale-Up互联,充分发挥低延迟特点 。
②互联方案
- 单节点内部采用高速铜缆或PCB走线。
- 跨节点Scale-Out采用InfiniBand或以太网(如QDR/FDR InfiniBand)
- 大规模集群采用2-tier或3-tier拓扑(Spine-Leaf、Super Spine架构)
③内存架构:HBM4高容量配置
MI455X单卡配备高容量HBM4,整机架31TB HBM4总容量超越英伟达NVL72的13.5TB。高内存容量使Helios在大模型推理场景中具有显著优势,可支持更大 batch size 与更长序列长度。
④散热技术:全水冷散热设计
Helios 72采用全水冷散热设计,计算托盘与整机架均配备液冷系统,确保高功耗芯片的稳定运行。实测散热效率比英伟达NVL72提升25%。
⑤软件栈与调度能力:提供CUDA替代方案
ROCm开源平台提供CUDA替代方案,支持PyTorch、TensorFlow等主流框架。AMD持续投入开源生态建设,降低开发者迁移成本。ROCm 7.2新增对MI350系列、MI400系列的深度优化,支持vLLM-d、DeepEP、SGLang等开源项目。
机柜方案
Helios采用标准化机架设计,单个计算托盘集成4 GPU + 1 CPU + 6 SmartNIC,多个托盘垂直堆叠形成机架。供电与散热系统针对高密部署优化,支持模块化扩展与维护。机柜重量约3吨(7000磅),其中液冷系统占据显著比重。
路线特点与差异化
AMD的核心差异化策略是开放生态:
开放互联标准:UALink联盟提供替代NVLink的开放选择,降低用户锁定风险。
开放软件栈:ROCm开源生态降低迁移门槛,吸引更多开发者。
后发追赶态势:相比英伟达,AMD在互联技术成熟度、软件生态完善度方面仍有差距,但差距正在缩小。
主流超节点方案05:
阿里云磐久系列

阿里云于2025年云栖大会发布的磐久AI Infra AL128是互联网云服务商超节点方案的代表作,后续规划扩展至UPN512(512卡)。该产品定位”一云多芯”的开放智算基础设施,由阿里云自主研发设计,可高效支持多种AI芯片,单柜128卡的密度刷新业界纪录。
磐久系列的发布标志着阿里云从”算力提供者”向”算力架构创新者”的角色升级。强调开放兼容——磐久AL128支持X86、ARM等多芯片架构,企业无需担心芯片选型绑定风险,实现”一云多芯”的灵活部署。
磐久AL128的单柜128卡密度在同期产品中处于领先水平,阿里通过创新的非对称双宽柜设计,在标准机柜空间内实现了更高的芯片集成度。10万卡级稳定互联的灵骏集群扩展能力,使其能够承载超大规模模型训练任务。
关键技术
①互联协议/拓扑:支持UALink,正交架构
磐久128采用Alink Switch节点架构,实现芯片间高速互联。内部电信号采用铜传输,上下节点间采用光信号传输,形成”铜-光”分层互联结构 。
UPN512采用单层光互联/单层CLOS网络拓扑,这是其核心创新点。通过光电引擎实现光电转化,利用光纤互联支持512个xPU的全互联。采用LPO(线性驱动可插拔光模块)和NPO(近封装光模块)混合光互联方案,相比传统方案实现成本降低、时延减少、功耗降低、可靠性提升 。
Scale-Up互连带宽:每颗GPU芯片预留最大128组高速互连SerDes,最高可达14T-28Tb的互联带宽 。
②互联方案:CIPU 2.0与EIC/MOC高性能网卡
- 采用无背板正交架构,Alink Switch与CIPU 2.0深度集成 。
- 分层互联采用”铜-光”结构:铜连接用于内部通勤,光连接用于跨区调度 。
③内存架构:数据本地化与内存带宽优化
磐久AL128通过优化内存访问路径,减少数据搬运开销。采用HBM3高带宽内存与CXL扩展内存的混合配置,配合CIPU的智能数据预取和缓存管理,提升有效内存带宽利用率。
④散热技术:全液冷与极致能效
磐久AL128采用全液冷技术,功耗密度提升至30kW/柜。无风扇设计使机房噪音从85分贝降至45分贝,满足企业级机房的环保要求。
⑤软件栈与调度能力
磐久AL128与阿里云的软件生态深度整合:飞天AI平台提供资源管理、作业调度、模型训练、推理部署的全栈能力;PAI(Platform of Artificial Intelligence)作为一站式机器学习平台,支持交互式建模、分布式训练、模型优化;灵骏集群调度系统实现10万卡级资源的统一管理和弹性伸缩。
机柜方案
磐久AL128的机柜设计充分体现”非对称双宽”理念——机柜宽度较标准19英寸机架增加,为128卡的高密部署提供物理空间。计算节点与交换节点的正交布局使机柜内部线缆长度最小化,信号完整性得到保障。
供电方案支持30kW/柜的高功耗密度,采用高压直流(HVDC)或48V直流配电,减少转换损耗。液冷系统的CDU(冷却分配单元)集成于机柜底部,冷却液通过Manifold分配至各计算节点,形成闭环循环。整机柜预制化交付,现场仅需连接外部冷却管路和电源,部署效率较传统方式提升10倍。
路线特点与差异化
磐久AL128的核心差异化在于“开放兼容+云原生深度整合”。阿里云强调”一云多芯”的灵活性——同一基础设施支持多种AI芯片,用户可根据性能、成本、供应等因素自由选择。这种策略降低了用户的供应商锁定风险,但也对阿里云的软件兼容性测试和优化能力提出更高要求。规模演进方面,从128卡到512卡的全光互连扩展,体现了阿里对更大规模超节点的技术储备。
主流超节点方案06:
腾讯云ETH-X开放超节点

腾讯云ETH-X开放超节点是由中国信通院、腾讯在ODCC(开放数据中心委员会)牵头发起的开源项目,定位为”开放的RoCE-based超节点方案”。与英伟达NVLink等私有协议不同,ETH-X采用更为开放的RoCE(RDMA over Converged Ethernet)方案,旨在降低超节点技术的准入门槛,促进产业生态繁荣。
ETH-X的”开放”体现在多个层面:协议标准开放(基于IEEE 802.3以太网标准)、硬件设计开放(参考设计供产业界采用)、软件接口开放(兼容主流AI框架)。这一策略使ETH-X成为互联网厂商、服务器厂商、芯片厂商共同参与的技术共同体。
ETH-X 64的基准配置包含64个GPU,整机柜提供204.8Tbps的GPU互联带宽,8个Switch Tray支持409.6Tbps的交换容量(一半用于柜内互联,一半用于柜间扩展)。
关键技术
①互联协议/拓扑:RoCEv2以太网与双平面架构
ETH-X的核心技术选择是RoCEv2(RDMA over Converged Ethernet v2),在标准以太网基础设施上实现RDMA功能,兼具高性能与成本优势,是替代InfiniBand的主流开放选择。
ETH-X采用双平面架构——计算平面与存储平面分离,优化流量调度。
②互联方案:GPU与交换芯片100G SerDes直连
ETH-X 64采用GPU与Switch芯片通过高速SerDes链路直连,整机柜带宽达204.8Tbps。8个Switch Tray支持409.6Tbps的交换容量,一半用于超节点柜内连接GPU,另一半用于背靠背连接旁边机柜的超节点或通过L2层HB Switch做更大的HBD域Scale Up扩展。
③散热技术:风冷/液冷可选配置
ETH-X作为开放架构项目,不强制规定散热方案,支持风冷和液冷两种选项。64卡规模可采用风冷设计,512卡规模建议液冷配置。
机柜方案
ETH-X采用模块化机柜设计,基础单元为Compute Tray(计算托盘),每个托盘配置4 GPU + 1 x86 CPU,实现计算与控制的紧密协同。机柜支持灵活扩展,通过增加Compute Tray与Switch Tray实现规模增长。供电与散热方案根据配置动态调整,支持标准数据中心环境部署。
ETH-X机柜的核心组件包括:Cable Tray(高速铜缆互联,盲插设计,整体交付)、Busbar(ORV3规范,导体横截面积与长度可定制)、Manifold&快接头(UQDB型盲插快接头,自动校准设计)、Power Shelf(集中供电,支持高功率密度)。
路线特点与差异化
腾讯云ETH-X的核心差异化在于“开放标准、产业协同”的定位。作为ODCC主导的开源项目,ETH-X打破私有协议垄断,实现不同厂商硬件的互操作性,降低用户总体拥有成本。ETH-X预计2026年实现规模化商用。
主流超节点方案07:
字节跳动大禹超节点

字节跳动推出的大禹超节点是基于其自研的“大禹”开放架构的AI算力基座,旨在打造弹性可扩展的整机柜算力解决方案。该方案融合了高密度液冷整机柜与灵活的网络利用率提升技术,支撑字节跳动内部大模型研发的核心计算需求。
单机柜规模:
·基本配置:单机柜设计支持 64或128卡 的AI计算卡(如GPU或NPU)。
·扩展能力:具备弹性扩展能力,理论上支持向 256卡 甚至更大规模的扩展,以满足更高算力需求。
最大集群规模:
大禹架构强调“弹性扩展”,在系统级互联、供电和制冷的支持下,单节点规模计划向 256卡或512卡 迈进,以应对万亿参数模型训练的需求。
关键技术
①互联协议/拓扑:EthLink自研以太网互联
大禹超节点最核心的技术创新是EthLink——字节跳动自研的GPU Scale-up以太网互联技术。EthLink的设计目标是替代昂贵的InfiniBand方案,在标准以太网硬件上实现高性能GPU互联。
EthLink的关键技术包括:OEFH优化报文头(替代ETH+IP+UDP标准头,报文开销显著降低)、RS-272低延迟FEC(替代标准FEC方案,链路层延迟大幅降低)、LLR链路级重传(发送端缓存,丢包重传,降低FEC要求,支持LPO光互联)、CBFC信用流控(交换机内部丢包防护,端到端可靠传输)。
②互联方案:GPU Scale-up优化
EthLink针对GPU Scale-up场景进行了专项优化:短报文处理、低延迟FEC、链路级可靠传输。这些优化使得EthLink在AI训练的典型通信模式(小数据包、延迟敏感)下,性能接近InfiniBand,而成本大幅降低。字节披露,其内部大规模部署验证了EthLink的可行性,在推荐模型训练场景下性能与InfiniBand相当,成本降低30%以上。
③散热技术和可靠性
散热方案:采用液冷整机柜 设计。通用计算液冷整机柜利用24个U位做计算节点,每个U位放置两个逻辑节点,单机柜提供48个通用处理器节点。制冷技术:除了CPU和GPU,内存、SSD、NIC、光模块等均采用冷板式液冷,以确保在高密度部署下的散热效率。
机柜方案
·高密度设计:单机柜设计采用液冷整机柜架构,通过紧凑的U位布局和双节点并排配置,大幅提升算力密度。
·供电方案:为了支持高密度和高功率的需求,下一代超节点计划采用 HVDC(高压直流) 供电方式,并在板级部分引入垂直供电设计,以降低板级供电损耗并提升供电效率。
路线特点与差异化
大禹超节点的核心差异化在于“自研EthLink降低互联成本”和“超大规模推荐场景优化”。
·高密度液冷+高效网络:与传统风冷机柜相比,大禹方案通过液冷整机柜提升了算力密度,并通过优化互联技术将网络利用率提升至95%以上,这是其显著的竞争优势。
·弹性扩展能力:大禹不仅是一个单机柜的算力节点,更是一个可以向更大规模弹性扩展的算力基座,这种从64/128卡向256卡甚至更大规模的无缝升级路径,是其核心差异化特性。
主流超节点方案08:
中科曙光ScaleX640

中科曙光于2025年11月发布的ScaleX640是全球首个单机柜级640卡超节点,由20余家AI产业链伙伴共同发起,开放覆盖部件级、系统层、基础设施层、软件层和数据集五个层面的技术能力。
ScaleX640采用创新的”一拖二”高密架构设计,单个机柜内实现640卡超高速总线纵向互连,两个超节点可组成1280卡计算单元,最终保障10万卡级超大规模集群的扩展部署。
在HPC+AI融合计算场景,ScaleX640的高密架构与曙光传统超算优势结合,支撑气象预报、基因测序、材料模拟等科学智能应用。
关键技术
①互联协议/拓扑:超高速正交架构与”一拖二”扩展
ScaleX640采用超高速正交架构设计,计算节点与交换节点垂直交叉部署,消除传统背板带来的信号衰减和带宽瓶颈。”一拖二”架构允许两个机柜通过高速线缆紧密耦合,形成逻辑上的单一计算单元,在保持单机柜完整性的同时实现规模扩展。这种设计在空间利用率与扩展灵活性之间取得平衡——单机柜满足中等规模需求,双机柜组合应对大型任务,万卡级扩展则通过标准网络实现。
②互联方案:16:1配比高速网络与scaleFabric扩展
ScaleX640的互联网络采用16:1的收敛比设计,即每16个计算节点共享1个交换节点的高带宽上行链路,在保证局部全互联性能的同时控制交换芯片成本和功耗。纵向扩展采用专用高速总线,横向扩展则兼容标准以太网/RoCE协议,实现Scale-Up与Scale-Out网络的融合统一。2025年12月发布的scaleX万卡超集群采用自研scaleFabric网络,实现400Gb/s超高带宽、低于1微秒端侧通信延迟。
③散热技术:浸没相变液冷与CDM液体冷凝
ScaleX640最引人注目的技术突破在于其散热方案——采用浸没相变液冷技术,将整个计算节点浸泡在低沸点冷却液中,利用液体相变(沸腾汽化)的潜热吸收芯片产生的大量热量。配备CDM(Coolant Distribution Module)液体冷凝换热装置,提供1.72MW的极致散热能力,支撑640卡满载运行。
机柜方案
ScaleX640的机柜设计充分体现”空间极致利用”理念。640卡计算节点、交换节点、电源模块、冷却液分配单元高度集成于标准机柜轮廓内,功率密度达到业界罕见的1.72MW/柜量级。机柜采用强化结构设计,承重能力和刚度针对液冷系统的额外质量优化。
供电方案采用高压直流(HVDC)结合分布式电源架构,减少转换层级损耗。浸没式液冷的冷却液循环需要精密流量控制,曙光设计了冗余泵组和智能阀门系统,确保单点故障不影响整体冷却循环。机柜维护采用前维护设计,关键部件支持热插拔,尽量减少对浸没环境的干扰。
路线特点与差异化
ScaleX640的核心差异化在于单机柜极致密度和浸没式液冷工程化。
主流超节点方案09:
超聚变FusionPod for AI

超聚变FusionPod for AI整机柜液冷服务器于2024年发布,定位企业级AI训练与推理场景。实现全球首个多元智算即插即用超级集群系统,单柜128张AI加速卡配置(注:64卡为标准配置,128卡为高密扩展)。
FusionPod for AI每个机柜容纳8台8 GPU模组节点,共64个GPU,单柜供电功率可达105kW。
关键技术
①互联协议/拓扑:InfiniBand或以太网可选
FusionPod for AI支持InfiniBand和以太网两种互联方式灵活组网,用户可根据现有网络基础设施和性能需求选择。
②互联方案:高速互联,支持多元算力灵活配置
支持多元算力灵活配置,优化互联效率。
③散热技术:第五代100%原生液冷技术
FusionPod for AI采用第五代100%原生液冷技术,冷板式液冷结合液冷背门,实现100%全液冷,pPUE低至1.06,节能超20%。相比风冷模式,GPU温度降低20℃以上,获得业界首个南德能效认证证书,液冷系统满足10年以上使用寿命,获莱茵液冷可靠性认证。
机柜方案
FusionPod for AI机柜核心设计:8台8 GPU模组服务器;三总线盲插(数据、管理、液冷);105kW高效集中供电,BusBar配电;冷板+液冷背门,100%液冷覆盖。
路线特点与差异化
FusionPod的核心差异化在于液冷能效行业领先(PUE 1.06),在可靠性工程与液冷技术方面具备深厚底蕴。
结语
超节点技术作为AI 算力基础设施的关键技术,正在经历快速的发展和演进。通过对主流厂商超节点方案的全面分析,我们可以看到技术创新的多样性和复杂性。
英伟达和AMD 通过芯片架构和互联技术的极致优化,在高端市场建立了技术壁垒;中国厂商通过系统集成创新和开放生态策略,在中低端市场找到了突破口;华为和谷歌则通过超大规模扩展技术,引领了超节点技术的发展方向。各大厂商通过差异化技术路线和产品策略,在市场中占据不同位置,共同推动超节点技术的普及与应用。