超节点算力革命(三)| 超节点关键技术揭秘
2026-01-28
以下文章来源于微信公众号——全球计算联盟GCC
【前文回顾】超节点是支撑万亿参数大模型的核心算力基础设施,由传统HPC集群、GPU密集架构演进而来,现进入全栈协同设计阶段。其通过统一高速互联与内存统一编址,将海量计算芯片深度耦合,构建高带宽、低时延的机柜级计算单元。技术路径分化为垂直整合(NVLink)与开放架构(华为UB灵衢、UALink等)两大阵营。核心组成涵盖计算芯片、HBM内存等核心器件,高速互联总线,液冷供电配套的硬件整机,及编译器、AI框架等软件生态。
AI大模型已将算力需求推升至前所未有的高度。算力超节点正是针对这一根本性挑战提出的架构级解决方案,是人工智能发展需求与计算技术演进共同作用的必然结果。超节点不是单一技术的突破,而是涵盖了芯片设计、高速互联总线、内存&存储、系统工程、软件定义、并行计算等多个层面的、高度协同的系统级创新。
01算力芯片(GPU/NPU)
超节点的本质是系统级创新,而非单一芯片的革新。然而,作为执行计算任务的基本单元,CPU和GPU/NPU的架构特性与协同模式,直接决定了超节点的计算效率和应用广度。
①GPU/NPU等AI加速器:AI并行计算的核心
GPU/NPU等AI加速器是超节点的核心算力来源。它们专为处理大规模并行计算任务而设计,专注于高吞吐量的矩阵/张量运算,是大模型训练和推理任务的核心算力载体。其设计的核心目标是最大化并行吞吐量和能效比。
②CPU:通用计算任务调度
负责运行操作系统、管理硬件资源、执行控制流逻辑、处理I/O以及为GPU/NPU准备数据。在超节点中,CPU负责初始化AI任务、管理数据集、向GPU/NPU集群分发计算任务、汇总计算结果,并与外部存储和网络系统进行交互。虽然CPU不直接参与主要的AI并行计算,但其性能(特别是单核性能和内存访问速度)对于减少任务准备和收尾阶段的开销,提升整个工作流的效率至关重要。
③片上系统级高速互联(Chip-to-Chip)
为了打破CPU与NPU/GPU之间传统的PCIe总线瓶颈,新型芯片设计采用了更高带宽、更低延迟的封装内或片间互联技术。芯片需集成多路高速串行互联接口,如英伟达的NVLink、华为的灵衢UB等 。这些接口的带宽(数百GB/s/方向)和延迟(纳秒级)远高于PCIe,是实现芯片间直接内存访问(DMA)和全对等互联的物理基础 。
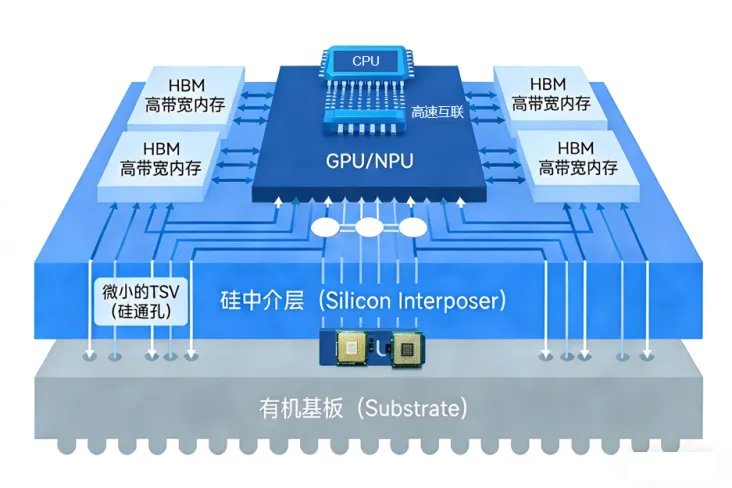
④高带宽内存(HBM)集成
HBM已成为高性能GPU/NPU的标配。通过3D堆叠技术,HBM在极小的物理空间内提供了TB/s级别的内存带宽,这是支撑NPU内部数千个核心并行计算的关键。超节点中的NPU普遍集成最新一代的HBM(如HBM3/HBM3e),是缓解“内存墙”的关键。
超节点中的CPU和GPU/NPU并非简单的组件堆砌,而是深度融合、协同优化的架构体系设计。通过片上高速互联打破通信壁垒,通过优化的内存体系匹配海量计算需求,为超节点在系统层面实现极致性能奠定了坚实的基础。
02大带宽低延时互联总线技术
超节点互联技术的目标是构建一个高带宽域。在此域内,任意两个计算单元(
CPU、GPU/NPU)之间的通信,具有接近芯片内缓存访问的带宽和可控的纳秒级延迟 。这需要从协议和硬件层面进行革新,构建的大带宽、低时延、无阻塞的算力高速公路。
①协议层深度优化
传统TCP/IP协议栈因其复杂的处理流程和多次内存拷贝,引入的延迟和CPU开销巨大。因此,亟需新型Scale-UP 总线技术突破限制,通过内存语义访问(Load/Store 原生指令直连)简化通信协议栈,省去冗余的封装与解封装流程。
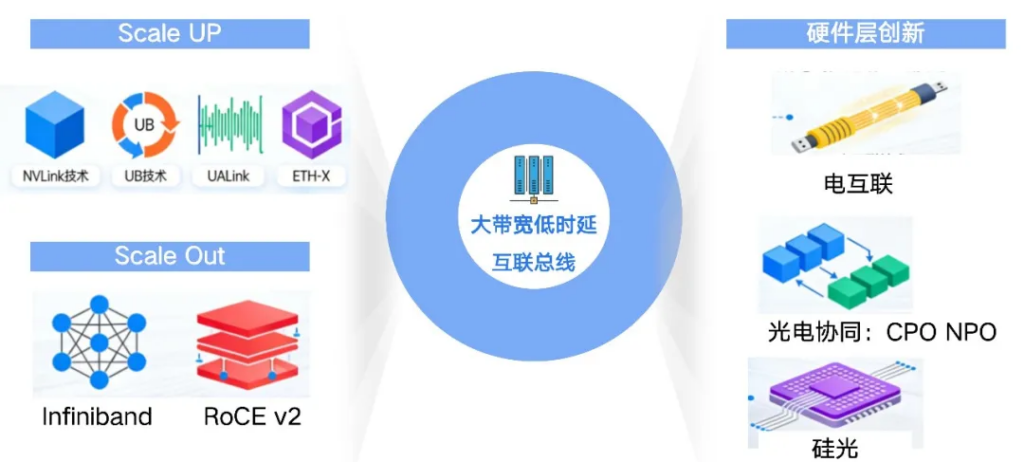
- Scale-UP:节点内的极致耦合
Scale-Up(纵向扩展)是指在一个物理机箱或紧密耦合的单元内,通过专用高速总线将多个AI加速器连接起来,形成一个逻辑上的“巨型加速卡”。这是超节点区别于传统集群的关键特征之一。
- NVLink:随着英伟达的Rubin架构的推出,NVLink也演进到了第六代,提供了TB/s级别的GPU间双向总带宽。通过NVSwitch芯片,可以构建全互联(All-to-All)的拓扑,使得机柜内的72个更多GPU之间可以进行无阻塞的点对点通信,共享巨大的统一内存 。
- UB (Unified Bus):由华为主导开发的高速互联总线标准。UB总线旨在为不同类型的计算资源(NPU, CPU, 内存、存储等)提供统一的、开放的互联接口,UB总线在协议层面实现了内存语义的直接访问(如Load/Store),支持跨芯片的缓存一致性。
- UALink:由AMD、Intel、Microsoft等巨头联合推出的开放互联标准,旨在抗衡NVIDIA的NVLink。UALink致力于为不同厂商的AI加速器提供统一的高速互联方案,其1.0标准已经发布,并计划在2026年左右推出性能更强的后续版本,为构建开放的异构超节点生态系统提供基础。
- SUE(Scale Up Ethernet):博通主导推出的AI 纵向互联技术框架,核心定位是填补传统以太网在高密度算力协同场景的性能空白,为超节点提供内存语义级高速通信支撑。其聚焦超节点内多 XPU 系统的规模化扩展需求,适配大模型训练等高频交互任务,通过优化通信协议与架构设计,实现低时延、高带宽的数据交互。
- ETH-X (Ethernet-X):腾讯等厂商探索使用以太网技术进行节点内互联。通过对以太网协议进行深度优化,并结合专用的高密度交换芯片,以太网同样有潜力在成本和开放性上提供一种有吸引力的选择,尽管在延迟和协议开销上相比专用总线仍有挑战。
- Scale-Out:跨节点的无缝扩展
当算力需求超过单个机柜所能容纳的极限时,就需要通过Scale-Out(横向扩展)技术将多个超节点机柜连接成一个更大规模的集群。Scale-Out互联虽然延迟和带宽相较于Scale-Up有所下降,但其性能仍然远超传统数据中心网络。
- InfiniBand (IB):专为高性能计算(HPC)设计的网络技术。它提供极高的带宽(目前已达800Gbps,即NDR)和极低的延迟(通常在微秒级别,甚至亚微秒) 。InfiniBand网络协议栈在硬件层面实现,绕过了操作系统的内核,通过RDMA (Remote Direct Memory Access)技术,允许一台服务器的应用直接读写另一台服务器的内存,极大地降低了CPU开销和通信延迟 。
- RoCEv2 (RDMA over Converged Ethernet):在以太网上实现RDMA功能的技术。它利用了以太网的普及性和成本优势,同时提供了接近InfiniBand的低延迟性能 。对于希望在现有以太网基础设施上构建高性能AI集群的用户来说,RoCEv2是一个非常有吸引力的选择。
②硬件层创新:从铜缆到光进铜退
为了支撑TB/s级的带宽和极低的信号损耗,互联硬件正在发生革命性变化,当前以“光电协同” 为主流演进方向。
- 电互联技术:超节点短距互联的方案,通过铜缆实现芯片、板卡及机柜内节点直连通信。支持112G/224G/448G Serdes 速率,实现机柜内百纳秒级时延,无光电转换损耗;技术成熟、成本可控,可靠性高;
- 光电协同方案优化:CPO(共封装光学)与NPO(近封装光学)成为高密互联首选。 CPO方案将光引擎与交换芯片封装在同一基板上,大幅缩短电通道长度,降低功耗,提升带宽密度 。NPO(近封装光学)核心是将光引擎移至靠近交换芯片的位置,二者作为独立封装体共置于高性能基板上,通过基板实现短距互联。
- 硅光技术(Silicon Photonics):通过在硅基芯片上集成光器件,实现光信号的产生、传输、调制和探测。它可以实现芯片间、板间甚至机柜间更高密度、更低功耗的超高带宽连接。
超节点互联技术的核心目标是实现“两个极致”:在节点内部(Intra-Node)和节点之间(Inter-Node)都提供尽可能高的带宽和尽可能低的延迟。
03 全局内存统一编址
与Load/Store内存语义
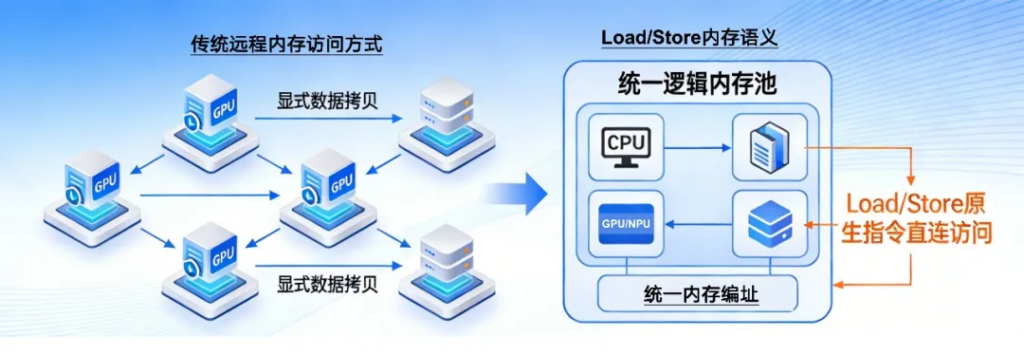
在传统的分布式计算中,每个节点(甚至每个GPU)都有自己独立的、物理隔离的内存空间。当一个计算单元需要访问另一个计算单元的数据时,必须通过显式的、由软件驱动的数据拷贝操作来完成。构建全局统一地址空间,将分布在各节点的物理内存抽象为单一逻辑内存池,支持Load/Store 原生指令直连访问,无需数据拷贝与序列化/反序列化操作,从协议层消除跨节点通信开销。
①全局内存统一编址
全局单一逻辑地址空间,为超节点内所有的计算单元(包括不同节点上的CPU和NPU)提供一个统一的、线性的逻辑虚拟地址空间。在这个模型下,任何一个内存地址对于系统中的任何一个处理器来说都是有效的,并且指向同一个数据。
意味着程序员不再需要关心数据物理上存储在哪一个GPU的HBM或哪一台服务器的DDR内存中。他们可以像在单机多线程编程中一样,直接通过指针来访问和共享数据,而无需手动管理复杂的数据传输。
- 硬件层支持:地址转换与缓存一致性
现代CPU和NPU/GPU都配备了内存管理单元(MMU)或I/O内存管理单元(IOMMU),负责将程序使用的虚拟地址转换为物理地址。在统一内存模型中,这些硬件单元需要能够处理指向远程物理内存的地址转换。硬件层面支持缓存一致性(Cache Coherence)协议 。当一个GPU修改了其缓存中的某块统一内存数据时,该协议能自动将这个修改通知并更新到其他可能缓存了该数据的GPU,从而保证所有处理器看到的数据都是最新的,避免了数据冲突 。
②Load/Store内存语义:通信即访存
Load/Store 内存语义:替代传统TCP/RDMA 的消息语义,支持跨节点内存的原生指令访问,数据交互无需应用层干预;
在支持Load/Store内存语义的系统中,一个GPU(或CPU)上的程序可以使用最基本的内存访问指令——“Load”(加载/读取)和“Store”(存储/写入)——来直接读写另一个GPU的内存,就如同读写自己的本地内存一样。要实现Load/Store内存语义,必须满足两个条件:
- 全局内存统一编址:必须有一个统一的地址空间,这样Load/Store指令中的地址才能被正确解析到远程内存位置。
- 超低延迟、高带宽的Scale-UP网络:网络延迟必须足够低(纳秒级),才能使得远程内存访问的开销接近本地内存访问,否则Load/Store操作会造成处理器长时间的停顿,反而降低性能。
Load/Store内存语义在需要高频、细粒度数据交互的并行计算场景中具有明显的优势。
- 张量并行(Tensor Parallelism):在训练大模型时,单个权重矩阵被切分到多个GPU上。在计算过程中,GPU之间需要频繁地交换中间计算结果(激活值)。使用Load/Store语义,一个GPU可以直接读取另一个GPU上的激活值,而无需复杂的同步和数据拷贝,极大地提升了计算效率 。
- 专家并行(Experts Parallelism):数据在不同专家(分布在不同GPU)之间路由和计算结果汇总时,同样涉及大量细粒度的数据交换,Load/Store语义能够显著降低通信开销。
Scale-UP互联协议通过其轻量级、高可靠的设计,为实现Load/Store内存语义提供了物理基础。而Load/Store内存语义则彻底改变了并行计算的通信范式,将节点间的通信开销降低到物理极限,是超节点能够高效执行紧密耦合并行任务的核心技术。
04高密度算力集成与能效优化技术
超节点的核心物理特征之一,是在极高的空间密度下集成海量的计算能力。这不仅是对计算架构的挑战,更是对系统工程、物理设计和能源效率的极限考验。
①高密度集成设计
高密度集成是超节点提升算力密度的核心手段,需在有限物理空间内实现算力规模化,同时控制能耗与散热压力。
机柜级创新:整个机柜被设计成一个有机的整体。机柜内部署了高速的电或光背板,直接连接各个计算节点,取代了传统杂乱的外部线缆,极大地提升了连接的可靠性和信号完整性。整机柜交付将供电、散热、计算、交换模块一体化设计,提升部署密度和效率。
②能效优化:追求极致的PUE
高密度集成必然带来惊人的功耗。一个满配的超节点机柜,其功耗可轻易达到数十甚至上百千瓦(kW)。
- 高压直流(HVDC)供电:超节点数据中心正在从传统的交流(AC)供电转向高压直流供电。HVDC减少了AC-DC和DC-AC之间的多次转换,显著降低了能量损失,提升了从电网到芯片的端到端供电效率 。
- 散热技术:空气的导热能力极差,当芯片功耗超过一定阈值后,风冷散热便会遭遇瓶颈。液体的比热容和导热系数远高于空气,因此液冷成为超节点散热的标配技术 。冷板式液冷(Direct-to-Chip Liquid Cooling):将内含微小通道的金属冷板(Cold Plate)直接贴合在CPU、NPU等主要发热部件上。冷却液在管道的驱动下流经冷板,高效地带走芯片产生的热量,被加热的液体随后流到机柜外部的冷却分配单元(CDU),经过热交换降温后再循环使用。浸没式液冷(Immersion Cooling):是更为激进和高效的散热方式,将整个服务器或所有计算刀片完全浸泡在不导电的特殊冷却液(如氟化液)中。芯片产生的热量直接传递给液体,通过液体的循环或相变(液体沸腾变为气体)来带走热量 。

高密度集成与能效优化是一体两面的工程挑战。超节点的成功,不仅取决于其峰值算力,更取决于其“每瓦特性能”。通过从芯片到数据中心的系统性节能创新,超节点才能在提供澎湃算力的同时,实现可持续发展。
05多级缓存池化与存储优化技术
对于超大规模AI模型而言,如何高效地存储、管理和访问海量参数(权重)、中间结果(激活值)以及训练数据集,是超节点设计的核心挑战之一。多级缓存池化与存储优化技术,旨在构建一个跨越不同速度、容量和成本的存储介质的“金字塔”,并通过智能化调度,确保数据在正确的时间出现在正确的位置。
对于超大规模AI模型而言,如何高效地存储、管理和访问海量参数(权重)、中间结果(激活值)以及训练数据集,是超节点设计的核心挑战之一。多级缓存池化与存储优化技术,旨在构建一个跨越不同速度、容量和成本的存储介质的“金字塔”,并通过智能化调度,确保数据在正确的时间出现在正确的位置。
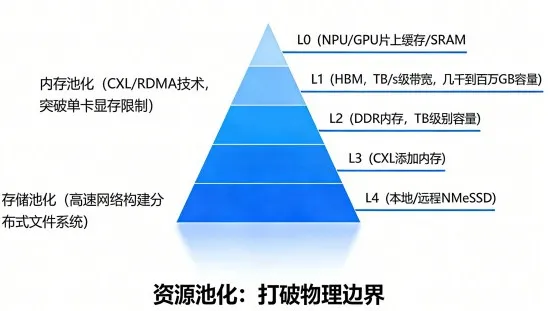
①超节点的深度存储层次
现代超节点的存储系统不再是单一的DDR内存或SSD,而是一个深度分层的体系:
- L0: NPU/GPU片上缓存/SRAM:速度最快(纳秒级延迟),但容量最小(MB级别),用于存放当前正在计算的数据和指令。
- L1: HBM(高带宽内存):集成在NPU/GPU封装内,提供TB/s级别的超高带宽,是存放模型权重和主要计算数据的核心场所,容量通常在几十到上百GB。
- L2: DDR内存:位于计算节点主板上,由CPU管理,容量较大(TB级别),带宽和延迟次于HBM,用于存放部分非热点模型参数、数据集缓存等。
- L3: CXL附加内存:通过Compute Express Link(CXL)总线,可以为节点挂载额外的DDR或SCM(存储级内存),实现内存容量的池化和动态扩展。
- L4: 本地/远程NVMe SSD:提供高速持久化存储,用于存放完整的训练数据集、模型检查点(Checkpoints)等。
②资源池化:打破物理边界
资源池化(Pooling)是超节点存储优化的核心思想。它通过软件定义和高速互联,将分散在各个物理节点上的存储资源(特别是内存和SSD)虚拟化为一个统一的、可按需分配的逻辑资源池 。
- 内存池化(Memory Pooling)
- 技术核心:利用CXL或RDMA技术,一个计算节点可以访问另一个节点的DDR内存,或者访问一个专用的内存池化设备。
- 应用价值:当训练一个巨大模型,其参数无法装入单个节点的HBM+DDR时,内存池化技术可以将模型参数分布在整个集群的内存池中。GPU在计算时,可以按需、透明地将所需参数加载到自己的HBM中。这对于大模型推理中巨大的KV Cache存储需求尤其重要,可以突破单卡物理显存的限制,支持更长的上下文处理 。
- 存储池化(Storage Pooling)
通过高速网络(如InfiniBand)将分布在多个存储节点上的NVMe SSD连接起来,构建一个高性能的分布式文件系统(如Lustre, GPFS)。所有计算节点都可以并发地、高速地访问这个统一的存储池,满足大规模分布式训练中对数据的高吞吐量读写需求。
通过多级缓存池化和智能存储优化,超节点能够有效地管理和调度PB级别的数据,为超大规模AI模型的训练和推理提供强大、灵活且高效的数据支撑,确保计算核心永远不会因为“等待数据”而空闲。
06并行计算策略与AI框架适配技术
超节点的硬件能力和软件调度能力,最终需要通过AI框架和并行计算库,转化为具体的模型训练与推理加速。这一层的技术负责将复杂的AI任务“翻译”成超节点能高效执行的指令流。
训练万亿参数的模型,必须将其拆分到数千个NPU上进行并行计算,这就需要并行计算策略与AI框架适配技术的协同工作(数据并行DP、张量并行TP、流水线并行PP、专家并行EP)。
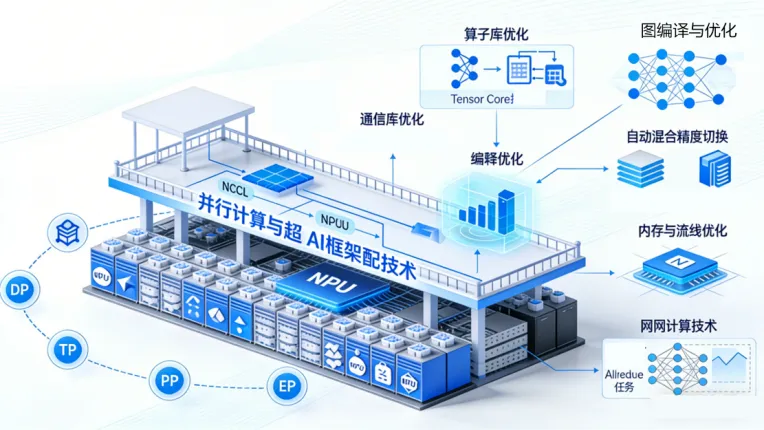
AI框架是实现上述并行策略的载体。为了适配超节点,现代AI框架进行了多项深度优化:
- 算子库优化:为超节点内的特定NPU/GPU开发高度优化的基础算子库(如卷积、矩阵乘、激活函数),并利用芯片的特殊指令集(如Tensor Core)和内存层次。通信库优化:集成或深度优化通信库,如NCCL、华为集合通信库(HCCL),使其能够充分调用NVLink、MatrixLink等超节点内部的高速互联路径,而非仅仅走外部网络 。
- 图编译与优化:框架的图编译器能够对计算图进行拓扑感知的切分和放置,自动选择最优的并行策略组合,并将计算子图调度到最合适的物理设备上。
- 内存与流水线优化:自动混合精度:框架自动管理FP16/BF16与FP32之间的类型转换和损失缩放,在提升算力的同时保证训练稳定性 。梯度检查点:在内存受限时,选择性不保存中间激活值,在反向传播时重新计算,以时间换空间。KVCache优化:在推理时,对Transformer模型的Key-Value缓存进行高效管理和复用,避免重复计算,是提升大模型推理吞吐量的关键技术 。
- 在网计算技术:将部分计算任务(如Allreduce、Broadcast)卸载至交换芯片,减少数据搬运开销;通过算子融合与流量编排优化,使集合通信吞吐量提升 30%, latency 降低 25%。
并行计算与AI框架适配技术,是连接上层AI算法与底层超节点硬件的桥梁。它的优化水平,直接决定了超节点理论算力能在多大程度上转化为实际的训练和推理加速比。一个与超节点深度适配的软件栈,能够像“老司机”一样,在复杂的硬件迷宫中找到最高效的任务执行路径。
07结语
算力超节点并非单一技术的突破,而是一场围绕“极致通信效率”和“高密度算力协同”进行的系统性工程革命 。它通过芯片微架构的互联亲和性设计、光电融合的大带宽低时延互联、创造全局内存视图的统一编址技术,在物理和逻辑上构建了计算域。通过高密度集成与液冷散热应对物理极限,通过软件定义调度与AI框架适配实现灵活高效的资源利用。最终,这台“性能猛兽”在强大而稳定的供电与散热生命线支撑下,将算力密度和有效利用率提升至新的高度。
更多超节点相关议题将在2026 Open AI Infra Summit上迎来集中探讨与实践交流。无论你是技术研发人员、企业决策者还是科研工作者,都能在这里突破瓶颈、链接资源、预判趋势。现大会预报名通道已开启,展位与赞助席位已同步开放,欢迎扫描下方二维码进入预报名通道,共话下一代算力格局!