HiFloat8高效训推技术亮相AAAI大会
2026-01-26
以下文章来源于微信公众号——全球计算联盟GCC
2026年1月20至27日,人工智能领域全球两大综合性顶会之一、由美国人工智能促进会(AAAI,Association for the Advancement of Artificial Intelligence)主办的第40届年度会议在新加坡举行。会上,华为AI处理器算法领域王鑫博士发表HiF8高效训推技术报告,向全球与会者介绍在模型训练和推理上进行HiF8量化的实践。HiF8此前已由华为开放给全球计算联盟GCC,并由GCC组织共建HiFloat生态。更多HiF8相关资讯欢迎持续关注GCC智算产发委。
AAAI年度会议始于1980年,近年每届参会人数在5000到8000人,通常包括论文宣讲、特邀报告、Workshop、技术成果展示等议程。来自华为的AI处理器算法领域专家王鑫博士在2026年度大会期间发表了HiF8高效训推技术报告,并向与会者介绍模型训练和推理上进行HiF8量化的实践。

AI模型算法专家介绍HiFloat8高效训推技术实践
数据格式设计
随着深度学习模型规模的不断增大,模型的训练和推理对计算效率、显存占用和能耗的要求也越来越高。低比特(8bit整型/8bit浮点)数据格式应运而生。其核心思想是使用更少的比特位来表示计算密集且对精度敏感度较低的模块,如模型参数(权重)和中间计算结果(激活值)等。HiF8作为一种新型的8位浮点数据格式,通过创新的即时可译、变长编码的Dot点位域设计,优化数据格式的动态范围和精度平衡,从而摆脱传统低比特数据格式对复杂细粒度缩放的依赖,实现更高效的模型训练和推理。
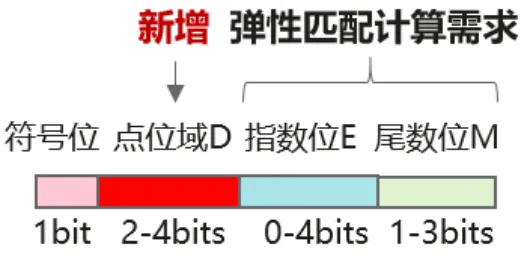
HiFloat8数据格式示意
验证实践
在模型训练方面,使用Current Scaling策略时,HiF8在粗粒度下(Per-tensor)可实现稳定且等效的训练性能;在Delayed Scaling策略下,HiF8在大规模模型预训练中能够保持与高精度BF16相当的收敛性能、精度无损或近乎无损,并显著提升端到端训练效率。
在模型推理方面,大多数推理任务可以直接采用粗粒度的量化策略,对整个张量(Per-Tensor)进行缩放,甚至进行无缩放(Scale-Free)转换。消除了大量缩放因子的管理,从而大幅简化推理框架和硬件加速器的设计,也降低了内存带宽和计算开销,从而充分地发挥8位计算的加速潜力。
HiF8此前已由华为开放给全球计算联盟GCC,并由GCC组织共建HiFloat生态。GCC智算产发委欢迎产业界伙伴一起,共同打造新一代低精度计算的全球产业高地。